From OpenCV to TensorFlow and back: fast neural networks using OpenCV and C++
TensorFlow is the most used deep learning framework today (based on the number of github stars), for a good reason: all important models can be and probably are implemented in TensorFlow and the tooling is really good (especially TensorBoard). For “classic” computer vision, that is computer vision not utilising deep-learning, OpenCV is the most important library* by far.
In recent releases the focus of OpenCV also shifted in the direction of neural networks: it is now possible to train multi-layer-perceptrons (MLPs) using the library, but it is also possible to run models trained in deep-learning frameworks such as TensorFlow.
For my bachelor-thesis i experimented with using an MLP for a simple classification task, with the main issue beeing inference speed on limit resources (no gpu is available on the target system). For this task i tried a variety of approaches with huge differences in performance, this is why i decided to sum up my results in this blog post.
From OpenCV to TensorFlow
I decided to train my first model using the OpenCV inbuild MLP library. The main reason was the ease of use, you set the number and dimensions of the layers, load the training data into OpenCV-Matrixes and call the train() function.
The usage was similarly easy, after saving the model i could just load load the model in my program and get predictions.

The simple usage had some major drawbacks: the training was running on a single CPU core, neither the 7 other cores nor the GPU was used. The training-process also had some severe limitations, there are no mechanism to prevent overfitting (such as dropout-layers or regularization). Furthermore it is not possible to se the progress of the training or to stop the training early and still save the model.
This is why i decided to switch to TensorFlow for training, this made loading the model into OpenCV more difficult, i had to run two python scripts for “freezing” and optimizing the graph to get from a checkpoint file to a protobuf file which can be read by OpenCV.
The problem
But the main problem was the inference speed, while my initial model was running in about 1ms the model imported from TensorFlow needed 5 to 8ms. For my application this time is the difference between easily doable and a no-go. Furthermore the first inference of the loaded model took about 200ms, this can be worked-around by running a first dummy-inference pass after loading the model, but this still requires 200 spare milliseconds at some time during startup.
And back
As a solution, i tried to combine the TensorFlow training process with the execution speed of the OpenCV-MLP implementation. After training a model in TensorFlow
it is easily possible to read the trained parameters (weights) from a file, additionally the OpenCV models are saved in easy to understand format
(either as xml or yml file). This means combining both programs just requires converting TensorFlow checkpoint files to OpenCV MLP files.
This brings some small limitations: the only transfer-function which is fully supported by OpenCV is the sigmoid-function. The library is also strictly limited to feed-forward lps, neither CNNs nor architectures with feedback are possible.
Transfer functions and their interpretation in OpenCV
As of Version 4.1 the only fully supported transfer function is the sigmoid function. According to the OpenCV-Docs it is defined as:
with and
which is identical to
.
This is not the sigmoid-transfer-function but the (also commonly used) transfer function.
When training a neural network with TensorFlow you need to keep this in mind, just select the tf.nn.tanh function, the conversion script automatically
sets and , so that .
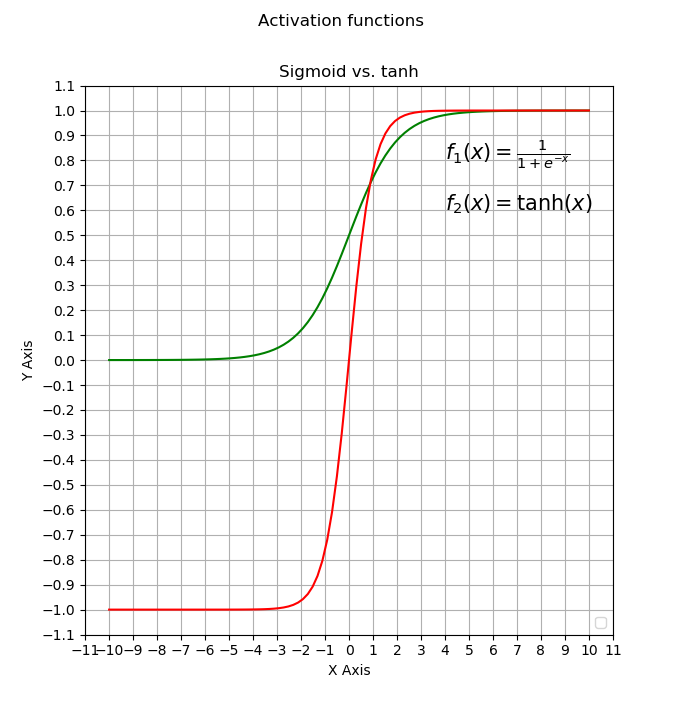
The second limitation is OpenCV not supporting different transfer functions for different layers. While a sigmoid is fine for the hidden layers, on the output layer you often want to apply the softmax function for classification tasks, or even the identity for approximation tasks. Luckily for us the function is bijectiv, which means there exists a function with which is the reverse function to . This function is the areatangens hyperbolicus ().
With this knowledge one can now either adapt the training data or the inference step to use arbitrary transfer-functions in the output layer. For simple classification tasks it is enough to replace the function by a softmax function during inference, which can be done by applying the function and then the softmax function.

For approximations task one need to adapt the training process as well, this can be done by applying the function on the training data. Due to the monotony the training should produce the similar results (assuming the absolute value of the approximation task is reasonably low), during inference one can now apply the function and get the real approximation.

Usage
My solution for the slow execution speed of TensorFlow models was converting them to OpenCV models. For this i wrote a small python script which reads a checkpoint file, which can be generated during training by the tf.train.Saver class and generates a xml file with the network definition for OpenCV.
To use the script, clone it from the github repo: github.com/aul12/Tensorflow2OpenCV and run the script:
python3 main.py model.ckpt output.xml
the first parameter is your checkpoint file. This file doesn’t exist in this form, instead there are some files which all start with this name, in my case they are called model.ckpt.data-00000-of-00001, model.ckpt.index and model.ckpt.meta. The second argument is the xml file to write to, be careful that the ending
is xml, OpenCV determines the file type by the ending.
After running the script, the model can be loaded by using the cv::ml::ANN_MLP interface
in your program.
Other options
What other options are there to run your deep-learning models with OpenCV? One option is to use the TensorFlow-C++ binding, but this requires building TensorFlow from source which will lead to some Cuda version problems, additionally getting the OpenCV images into the tensor-format is difficult and will produce some overhead.
An other alternative is to use a different deep learning framework, such as PyTorch or Caffe. As my goto framework is TensorFlow i have less experience using other frameworks, but for example with PyTorch it is quite difficult to run the model using C++ and even requires some intermediate language called TorchScript.
Footnote:
* im differentiating between TensorFlow as a framework and OpenCV as library. This differentiation is based the “Hollywood Principle”: “you call a library but a framework calls you”.